在前面的 3 篇文章,我們先是對 dbt/SQL 做了整體概括性的介紹,並且安裝好了一個精簡版的現代資料棧 (modern data stack),於是,我們可以開始透過一個實際的例子,帶著讀者們來體驗一下, dbt 是怎麼使用的。
dbt 官方有提供一個可以用來快速起步的專案 jaffle_shop , jaffle_shop 專案建議搭配的資料倉儲有兩種:Postgres 與 DuckDB 。接下來,我們會用 DuckDB 來玩玩看 jaffle_shop
~/analytics 做為存放所有「分析專案」的資料夾。~/.dbt/profiles.yaml 檔jaffle_shop:
target: dev
outputs:
dev:
type: duckdb
path: jaffle_shop.duckdb
這邊簡單解釋一下這個環境設置:
jaffle_shop ,這個字串需要跟專案資料夾的資料夾名稱一致。target 現在是指向 dev 。一般而言,我們在 dbt 的專案,會有 dev 與 prod 兩種設置。dev 是開發的時候用的、而 prod 才是正式布置時使用的。outputs 下方的 dev 這邊的細節通常是與資料倉儲 (Data Warehouse) 相關的。type 會用來指定是哪一種資料倉儲。如果是 Postgres 的話,這邊就會有 host/post/user/password 之類的設置。因為我們現在是用 DuckDB ,所以最簡單的設置,只需要設定 path 而已,而此處的 path 就是 DuckDB 儲存資料的檔案。這邊有一個問題:「我們怎麼知道,我們把『環境設置檔』設定對了?」dbt 提供了一個非常有用的指令可以幫助我們回答這個。
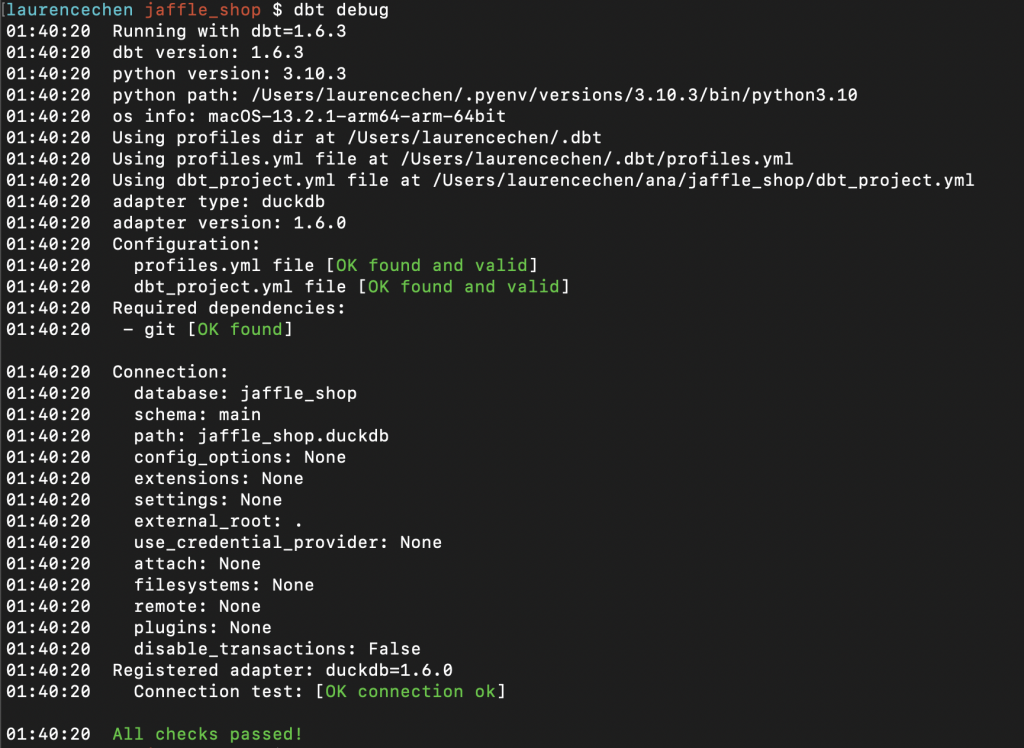
如果 dbt debug 得到的輸出,有綠色而沒有紅色的話,就代表成功了。
一般來講,如果能看懂 dbt debug 的輸出的使用者,通常在日後,遇到操作的問題時,都相對有機會快速地排除困難,然後前進。
當然,要能看懂 terminal 的輸出這件事是相當專業的,需要的知識更是遠超過一般資料分析師需要的範疇。換句話說,如果看不懂的話,也許就值得考慮 dbt cloud ,又或是公司的資料團隊要有軟體工程專業的人可以協助排除困難。
在執行過 dbt debug 之後,dbt 就會自動幫我們在 jaffle_shop 的資料夾下,建立一個新的檔案 jaffle_shop.duckdb 。而這個檔名,自然就是我們之前在 ~/.dbt/profiles.yaml 指定的。
下圖我們執行了:
duckdb 開啟 jaffle_shop.duckdb
SHOW TABLES
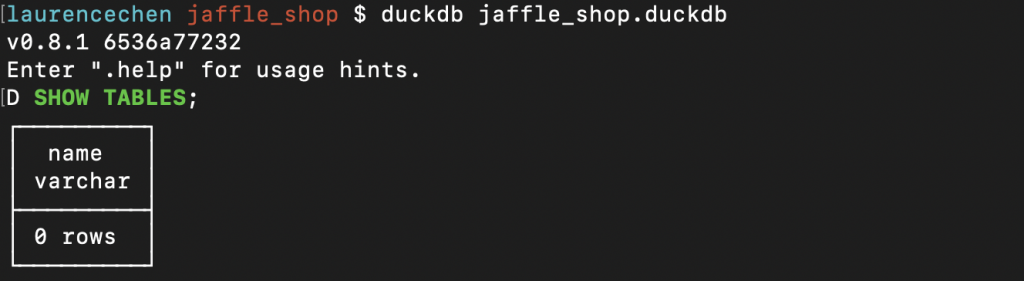
得到一片空白。這是正常的,因為還沒有匯入資料嘛!
.exit 就可以離開 DuckDB 的環境。要匯入資料,我們可以先用一個偷吃步的方式,透過 dbt seed 這個指令,把 jaffle_shop/seeds 資料夾下的三個 csv 檔,都匯入 DuckDB 裡。
執行完之後,再開啟 jaffle_shop.duckdb 來看。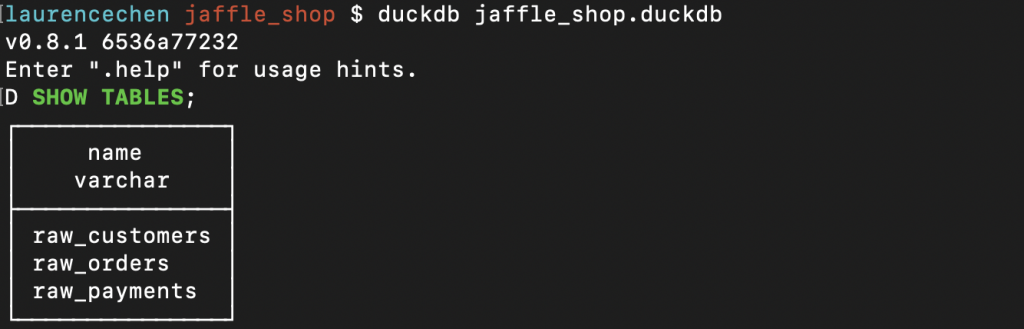
一般的 dbt 專案,其實不會常用 dbt seed 指令來匯入大量的資料.只有少數的 dimensional data 適合用 dbt seed 來匯入而已。但是,現在的這個專案只是範例而已,就一切走最簡單的路線。
當資料倉儲已經有了資料之後,我們就可以來進行最重要的部分:「編譯與建立視圖」。編譯是把 jaffle_shop/models 資料夾下的 *.sql 檔,做字串取代,變成可以執行的 SQL statement 。而建立視圖的話,則是把編譯完成的 SQL statement 做執行,在資料倉儲建立視圖。
「編譯與建立視圖」這個動作,是用 dbt run 這個指令來啟動。
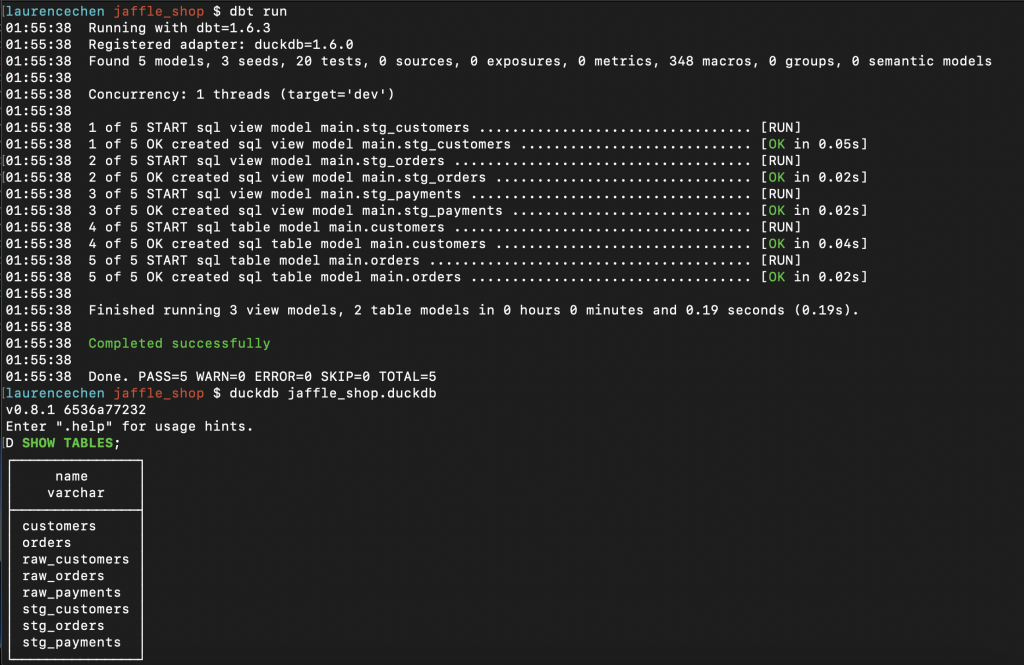
「編譯與建立視圖」完成之後,我們用 SHOW TABLES 一看,就會發現多了許多的視圖。
dbt 可以透過下指令來自動生成文件、與資料譜系圖 (data lineage graph) 。其中,資料譜系圖可以呈現視圖與視圖之間的依賴關系,一旦當資料的複雜度增加時,這張圖就會變得非常重要。
執行完上述的指令之後,就可以得到下圖。
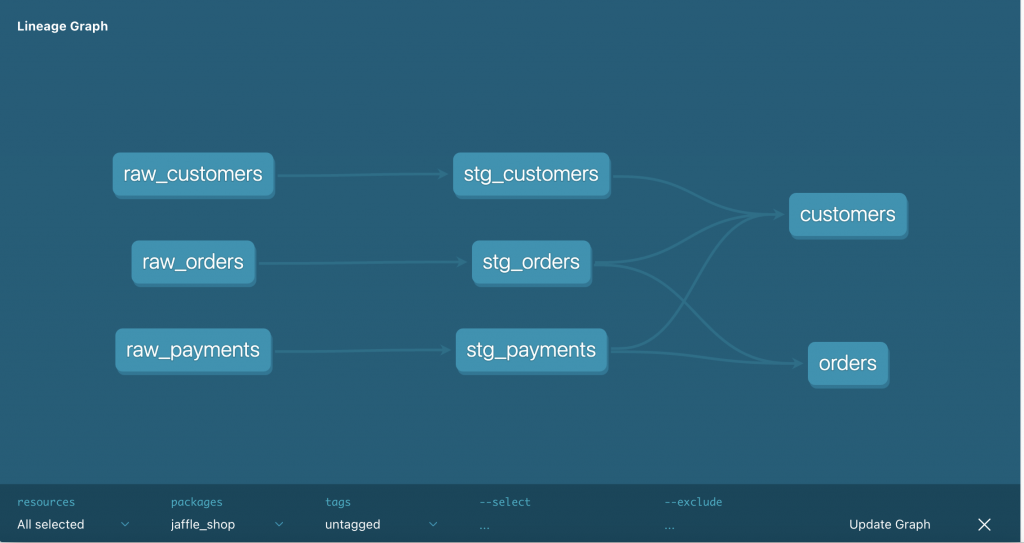
如果是從零開始的話, 最基本、最簡單的 dbt 專案大概會是以如下的步驟來運作:
dbt init $PROJ 來生成基本的資料夾結構。$PROJ 資料夾加入版本控管軟體。~/.dbt/profiles.yaml 檔,把環境設置檔做對,於是 dbt 就可以與資料倉儲 (data warehouse) 連上。$PROJ/models 下的 sql 檔,在其中寫入 資料轉換 。之後,如果又有要寫什麼新的資料轉換,就會再回到步驟 4 來寫新的 sql 檔。dbt run 。註:
$PROJ/models 下的 sql 檔,這些 sql 檔當然也要納入版本控管。dbt seed 這個步驟。

 iThome鐵人賽
iThome鐵人賽